행, 열 선택하기
import pandas as pd
friend_list = [
['John', 20, 'student'],
['Nate', 30, 'teacher'],
['Jenny', 40, 'developer']
] # list
column_name = ['name', 'age', 'job']
df = pd.DataFrame.from_records(friend_list, columns = column_name)이런 데이터프레임이 있을 때,
# 선택
df[1:3] # 1부터 2행까지 선택(연속)
df.loc[[0,2]] # index로 0번과 2번행 선택(불연속)
# 조건에 따라 필터링
df[df.age > 25] # 나이가 25 초과인 데이터
df.query('age > 25') # 이렇게 query 사용도 가능하다
df[(df.age > 25) & (df.name == 'Nate')] # 여러개의 조건 사용
필터링하기
Index로
friend_list = [
['John', 20, 'student'],
['Nate', 30, 'developer'],
['Jenny', 40, 'dentist']
]
df = pd.DataFrame.from_records(friend_list)
df.iloc[:, 0:2] # 모든 row를 보여주고, 0-1까지의 column을 보여줘라
column 이름으로
df = pd.read_csv('data/friend_list_noheader.txt', delimiter='\t', header=None, names=['name', 'age', 'job'])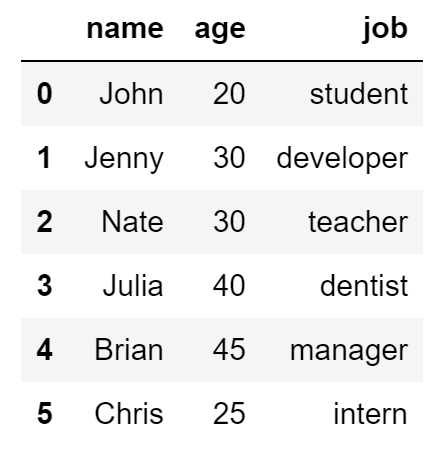
df_filtered = df[['name', 'age']] # name과 age column 데이터만 보겠어
df.filter(items=['age', 'job']) # filter함수를 쓰면 더 효율적으로 할 수 있음
df.filter(like='a', axis=1) # column 이름에 'a'가 들어간 것을 찾자
df.filter(regex='b$', axis=1) # 정규식을 사용하여 찾을 수 있다'Python > 기초공부' 카테고리의 다른 글
| [python] 파이썬 내장함수: zip(), reversed() (0) | 2020.04.20 |
|---|---|
| [Pandas 기초] 행, 열 삭제/생성/수정 (0) | 2020.03.31 |
| [Pandas 기초] 파일에서 데이터 불러오기 / 데이터프레임 생성하기 / 데이터프레임 파일로 저장하기 (0) | 2020.03.31 |
